
Summary
Plug this into Claude Desktop or Cursor and your AI gets twelve tools for verifiable math: search across a 3.68 million document index of theorems and arXiv papers, identify numeric constants via PSLQ at 50-digit precision, match integer sequences against a local OEIS copy, verify formal proofs through Lean's typechecker, and decompose theorem applicability into atomic precondition checklists. No LLM calls happen inside the server. It returns raw data for the AI to reason over. The headline is zero false positives: numeric verification re-evaluates at high precision, sequence matching is exact term lookup, formal verification runs the actual Lean kernel. Install with uvx, no API key needed. The retrieval tier gracefully degrades when optional datasets are missing.
Integrate web data into your AI product. One API to scrape website & brand data.
Get API Key Now →belt cli automatically finds the best tools and skills for your agent. image, video, music, tts...
one prompt install →Give your AI agent a complete email layer—sending, inbound inboxes, and sandbox testing.
Get 4K emails/month free →Agent, run crypto. Access onchain data & trade routes via 1inch.
Install now →Notes, actions and memory. Without a meeting bot. First month 100% off.
Download for free →Your agent targets a perfect 10 Code Health score. Deterministic. Every commit.
Try For Free →

mathlas

![]()



Available on mcp.so · Glama · listed in awesome-mcp-servers and best-of-lean4.
An airtight-math tool an AI uses — no LLM, no API key, free. Plug it into Claude Code, Cursor, or any MCP client. The AI is the brain; mathlas is the hands — it gives the AI the capabilities it lacks and returns data (candidates, verdicts, checklists, scaffolds) for the AI to reason over. Apache-2.0. The code is free for any use; published corpus/index artifacts carry their own per-source terms (CC-BY/CC0).
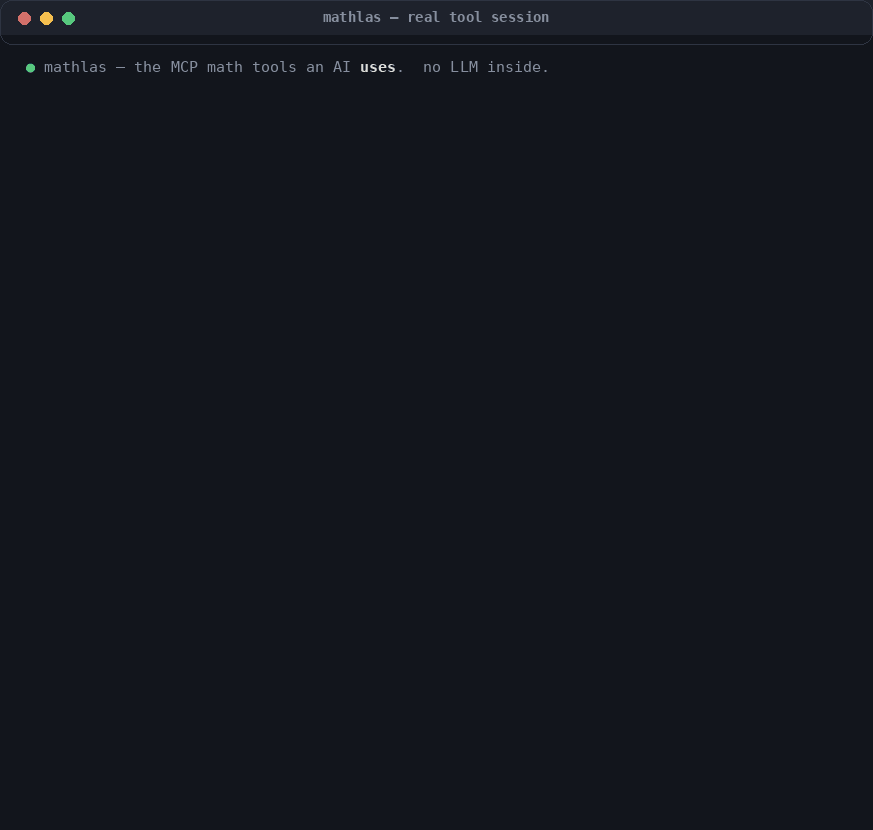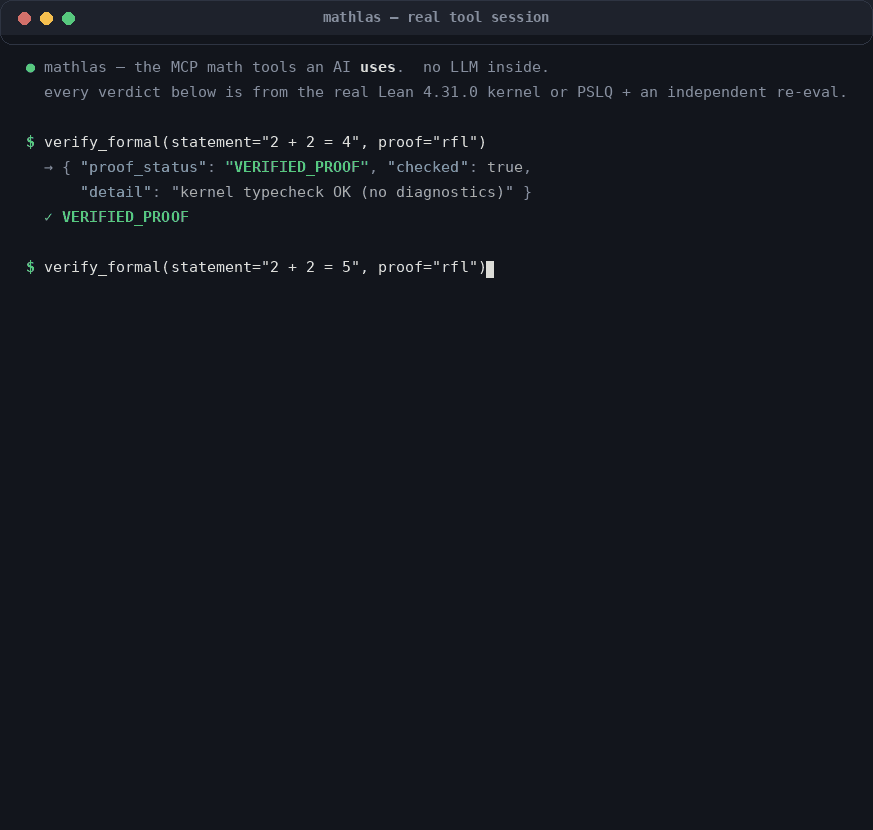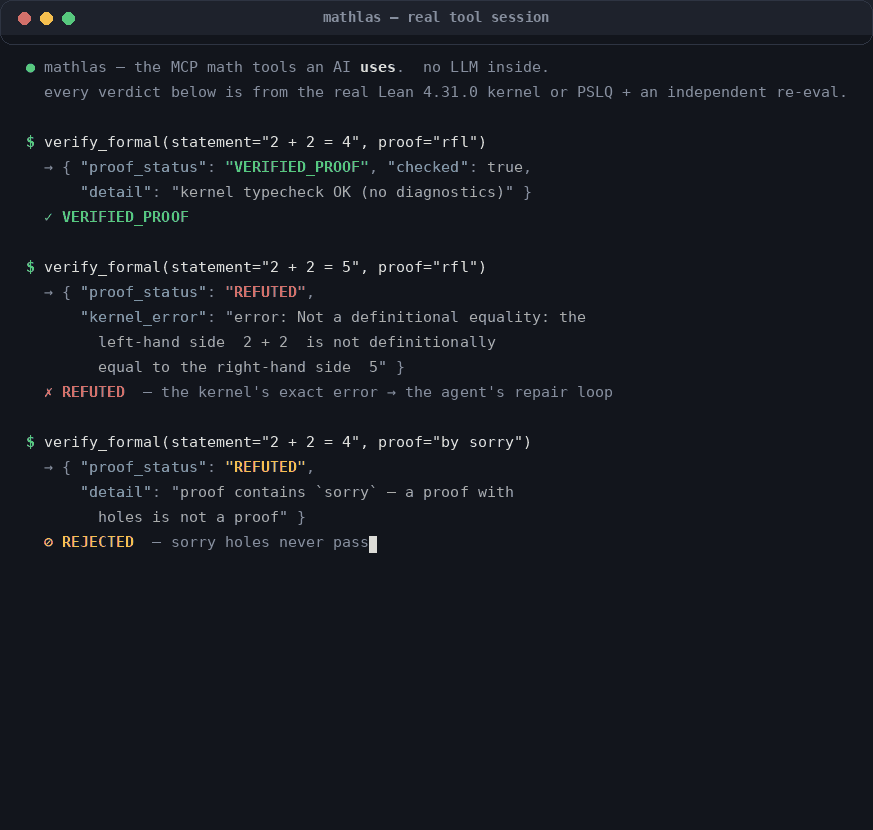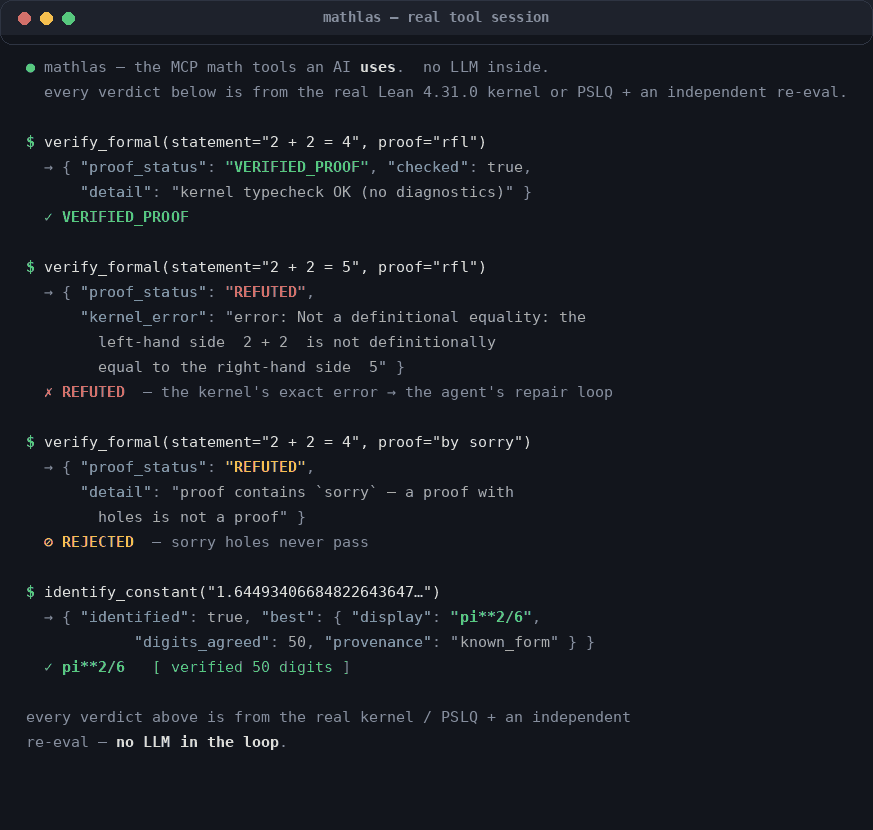
Every verdict from the real Lean 4.31.0 kernel / PSLQ + an independent re-eval — no LLM inside. Real in-process tool outputs, captured by assets/gen/capture_outputs.py.
Is this for you?
- You use Claude Code / Cursor and want your AI to stop hallucinating math —
search_existing_mathfinds the real theorem from a 3.68M-doc index;verify_numericandverify_formalcheck claims with zero hallucination risk. - You have a numeric constant or integer sequence you can't identify —
identify_constantruns PSLQ + closed-form matching (50-digit precision);identify_sequencedoes an exact OEIS term-match. - You need the formal (Lean/mathlib) name of a result —
search_formal_mathproxies the public Loogle + LeanSearch services and returns declaration names + types, provenance-labeled. - You're building an agent pipeline that needs airtight math in the loop — all 12 tools are pure data-returning MCP tools, no LLM inside, composable with any framework.
Install & register with Claude Code (no API key)
One line, nothing to install first (needs uv):
claude mcp add mathlas -- uvx mathlas-mcp
uvx mathlas-mcp fetches + runs the server in an isolated env on first use. Prefer pip?
pip install mathlas-mcp # core: numeric + retrieval + verify + scaffolds
pip install 'mathlas-mcp[mcp]' # + official MCP SDK
pip install 'mathlas-mcp[retrieve]' # + pyarrow, to read the real index
pip install 'mathlas-mcp[embed]' # + sentence-transformers/torch, for the Qwen3 embedder
claude mcp add mathlas -- python -m mathlas.server
mathlas now appears as twelve tools the agent can call. The server prefers the official mcp SDK and falls back to a dependency-free stdio JSON-RPC server if mcp isn't installed — it always runs. (Cursor / any MCP client: point it at the same uvx mathlas-mcp or python -m mathlas.server stdio command.)
Optional local data (degrades honestly):
identify_sequencewants a local OEIS copy;verify_formalwants a Lean toolchain. Without them the tools return a clear "data/toolchain not available" — never a fake answer. Seedocs/methods.mdfor the one-line setup of each.
A worked example — an AI using the tools
User: "Does x = cos(x) have a unique solution I can reach by iterating?"
AI → search_existing_math("contraction mapping unique fixed point complete metric space")
← [{name:"Banach Fixed-Point Theorem", statement:"Let (X,d) be a complete metric
space and T a contraction. Then T has a unique fixed point ...", ...}, ...]
AI → applicability_checklist(banach.statement)
← preconditions: ["(X,d) is a complete metric space", "T: X→X is a contraction"]
conclusion: "T has a unique fixed point"
AI (reasons): [0,1] is complete; cos is a contraction there (|cos'|=|sin|≤sin 1<1).
Every precondition holds ⇒ Banach applies ⇒ unique fixed point, reachable by iteration.
AI → verify_numeric("0.7390851332151607", "<the Dottie-number closed form, if claimed>")
mathlas supplied the search, the checklist, and the airtight numeric check. The AI did the judging. No LLM was called inside mathlas.
Results
The discipline is airtight-or-nothing: a result is an independently-checkable fact or an honest "nothing." The false-positive rate is 0 across every tier (full tables + commands in RESULTS.md):
| Tier | Recovery@known | False-positive | Why it's airtight | Benchmark |
|---|---|---|---|---|
Numeric (identify_constant) | 8/8 | 0/3 | independent high-precision re-eval (50–51 digits) | benchmarks/numeric_bench.py |
Sequence (identify_sequence) | 8/8 (7 top-1) | 0/3 | exact term-match vs local OEIS (~400k seqs) | benchmarks/tier_bench.py |
Formal (verify_formal) | 7/7 verdicts | — | real Lean 4.31.0 kernel typecheck | benchmarks/tier_bench.py |
Ramanujan (conjecture_relation) | 6/6 | 0/2 | PSLQ + CF, every hit re-verified ≥25 digits | benchmarks/tier_bench.py |
| Applicability moat | 15/15 decomp + 6/6 catch | — | atomic preconditions, misapplication traps | benchmarks/moat_bench.py |
| FunSearch + web-aug | 14/14 | — | sandbox containment (network / timeout / memory) | benchmarks/tools_bench.py |
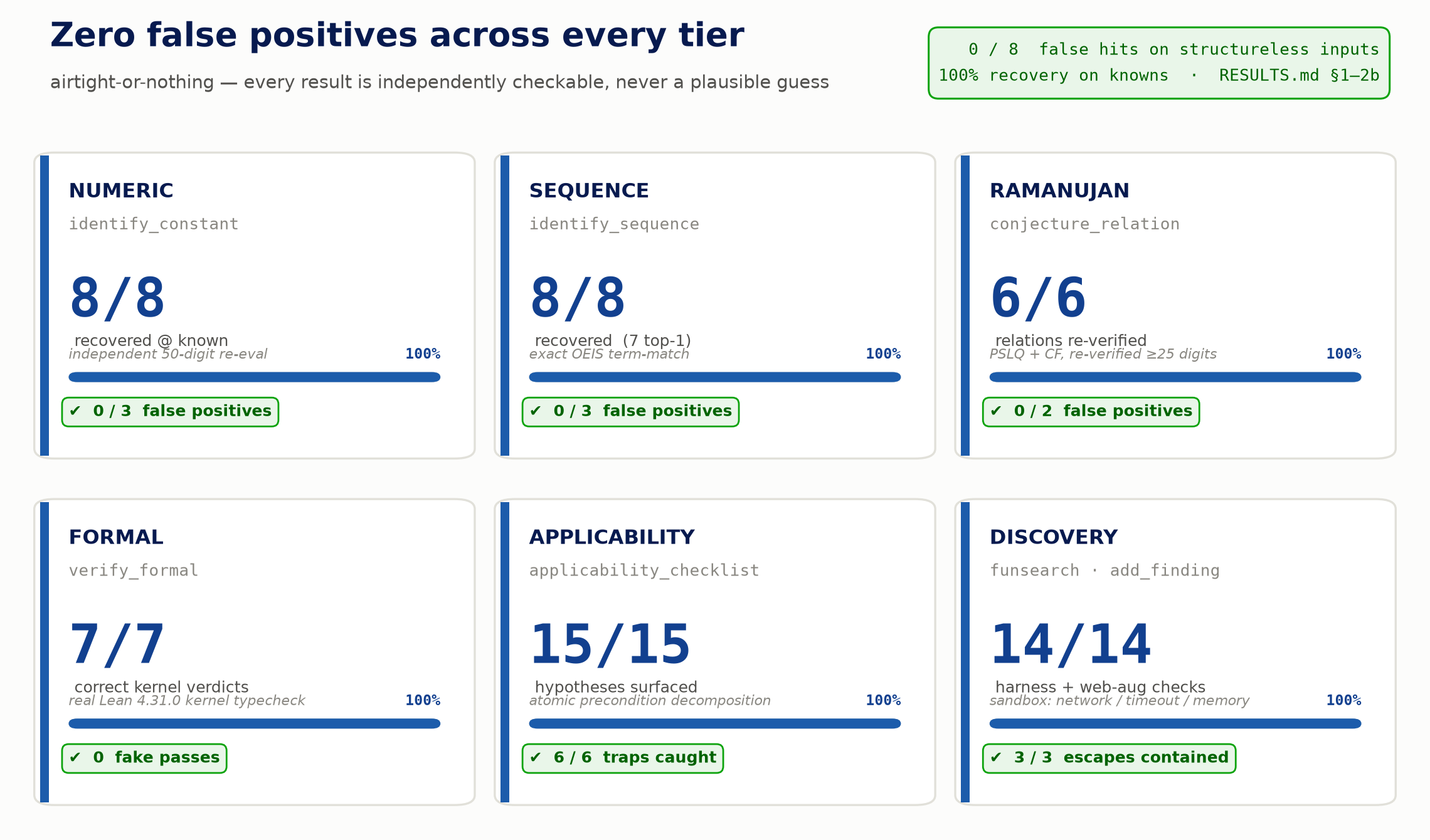
The table above, at a glance — 0 false positives across every tier (0/8 structureless inputs produced a false hit), 100% recovery on knowns. Numbers: RESULTS.md §1–2b.
Agent-in-the-loop, honestly reported (2026-06-10, Claude Fable 5): the same headless agent given 18 math tasks WITH the live mathlas MCP server as its only tool vs WITHOUT any tools scores 18/18 vs 15/18. The original 10-task set is saturated (10/10 both ways: a frontier model passes it from parametric knowledge alone, and we say so plainly), so an 8-task hard set was added where verification, not recall, is the bottleneck: that set goes 8/8 WITH vs 5/8 WITHOUT. The bare model times out on 50-digit integer-relation detection (PSLQ) and cannot name obscure OEIS sequences that shadow Catalan/Fibonacci prefixes and only diverge at depth. The bare passes it does earn are remarkable and we report them: it evaluated a 6-term constant relation to 45 digits by hand (residual 1.475e-27, correct), simulated IEEE-754 rounding bit-for-bit in its head (with one wrong exponent in prose), and proved a Machin-like formula exactly via Gaussian integers, all in-context at 3-9x the latency of a tool call. Every ground truth is a deterministic computation recorded in the bench; full table and provenance: RESULTS.md §2c. Run: benchmarks/agent_bench.py.
The 3.68M-doc index. search_existing_math is served from a 3,683,428-document dense index (Qwen3-Embedding-8B, 4096-d): the 1.34M permissive CC-BY/CC0 TheoremSearch subset + 2.34M slogan-embedded arXiv-math documents from Dolma, dense + Okapi-BM25 + RRF. Honest headline recall at full 3.68M scale: R@1 0.614 / R@10 0.832 querying by a document's raw body against its slogan-embedded entry — the hard cross-representation self-recall regime. (At the earlier 1.635M build, the easier same-representation slogan→slogan self-recall was R@1 0.977 / R@10 0.998 on its 81,833-doc held-out split.)
Open corpus on Hugging Face. The text + metadata side of that index is published at kattri15/mathlas-corpus: 3,683,428 theorem-level documents plus the small findings config, split into theoremsearch, dolma, and findings configs. It includes slogans, LaTeX statements, source URLs, titles, labels, categories, citation counts where known, and provenance keys. It does not include the 30 GB embedding matrices or local benchmark slices. Licenses are per config: TheoremSearch subset CC BY-SA 4.0, Dolma statements ODC-BY 1.0 with our slogans CC BY 4.0, and findings CC BY 4.0. Full audit: docs/HF_DATASET_LICENSING.md.
from datasets import load_dataset
ts = load_dataset("kattri15/mathlas-corpus", "theoremsearch", split="train")
dolma = load_dataset("kattri15/mathlas-corpus", "dolma", split="train")
Quantized laptop tier (opt-in). The fp16 matrix is 30 GB on disk (~60 GB fp32 resident) — fine on the build box, not on a laptop. MATHLAS_QUANTIZED=binary (or quantized="binary" on HybridRetriever.from_index) serves the SAME index from memmapped quantized sidecars instead: sign-bit Hamming over 1.9 GB shortlists 1000 candidates, exact rescore picks the top-k — measured on the full 3.68M index with the same n=3000 protocol as the headline, it is recall-lossless (R@1 0.6143 vs 0.6140 fp16, R@10 equal at 0.8323; int8 mode: R@1 0.6147, 15 GB) at 2.4 s/query on 4 CPU threads. Honest caveat: this shrinks the document side only — queries must still be embedded by the same Qwen3-Embedding-8B (a small 0.6B encoder lives in a different vector space). The true end-to-end small-encoder tier is the 0.6B tier below. Numbers, build command, and the caveat in full: docs/QUANTIZED_TIER.md.
0.6B end-to-end laptop tier (opt-in). The SAME 3,683,428-doc corpus re-embedded once with Qwen3-Embedding-0.6B (1024-d, row-aligned with the served meta), so the query encoder itself runs on a laptop CPU: MATHLAS_ENCODER=0.6b (composes with MATHLAS_QUANTIZED=binary). Measured with the identical n=3000 cross-representation protocol, queries re-encoded by the 0.6B model: R@1 0.545 / R@10 0.745 (binary + int8 rescore; the 0.6B fp16 exact scan is 0.544 / 0.745, so quantization is again lossless within the tier). The honest price vs the 8B tier (0.614 / 0.832) is about 7-9pp recall; the dual-channel 8B configuration (0.965 / 0.999) stays the big-box quality ceiling. The laptop headline: end-to-end 0.67 s/query on 4 CPU threads (0.88 s on 2), query encoding included, over all 3.68M documents. Dense-channel footprint: binary sidecar 0.47 GB + 0.6B encoder ~1.2 GB (~1.7 GB; int8 rescore source 3.77 GB recommended; full fp16 sibling index 7.54 GB). On the TheoremSearch-110 corpus-only probe the tier scores Hit@20 8.2% / 10.0% theorem/paper vs the 8B tier's 10.0% / 11.8% (both licensing-bounded floors). Full tables, footprints, and caveats: docs/QUANTIZED_TIER.md; build: scripts/build_06b_index.py; eval: scripts/eval_06b_tier.py.
Dual-channel retrieval (opt-in). The 0.614 headline is a cross-representation gap: LaTeX-statement-shaped queries searched against slogan-embedded docs. A second dense channel embeds the same 3,683,428 docs by their cleaned LaTeX statement (Qwen3-Embedding-8B, row-aligned, built by scripts/build_statement_channel.py) and folds into the dense ranking by per-doc max-sim. Measured on the same n=3000 sample at full corpus scale: R@1 0.614 to 0.965, R@10 0.832 to 0.999. Honest caveats: that eval is a self-retrieval proxy in which the statement channel indexes the very text the queries are drawn from (an exact-text advantage, like BM25's); on the no-leak 110 human-query benchmark the lift is real but partial (paper Hit@20 11.8% to 12.7%). And the second matrix roughly doubles serving RAM (measured at full scale: 150 GB process peak for the dual server vs ~95 GB single-channel; ~2.75 s/query dual dense scan on 2 CPU threads), so it ships strictly opt-in (MATHLAS_STATEMENT_INDEX=/path/index_full_statement.npz, never auto-detected) and is not combinable with the quantized tier. Full numbers and the serving-tier table: docs/RETRIEVAL_UPGRADE_NOTES.md. The production hybrid default rrf_k is 10 (measured best at every k tested), plus an opt-in cross-encoder rerank blend (MATHLAS_RERANK=1, Qwen3-Reranker-0.6B, +1.7pp R@1 honest lift). The rerank backend is selectable with MATHLAS_RERANK_MODEL: qwen3 (default, Qwen3-Reranker-0.6B, unchanged) or jina-v3 (jinaai/jina-reranker-v3, arXiv:2509.25085 — a 0.6B "last but not late" reranker that leads BEIR at the 0.6B scale). Both lazy-load their weights on first use and fall back to the un-reranked fusion (honest stderr note) if torch/transformers or the weights are absent; a typo'd model name raises rather than silently serving the wrong reranker. We ship the wiring, not a jina benchmark number — bring your own weights.
The self-augmenting loop — beating TheoremSearch
On TheoremSearch's own 110 human-written queries, baseline mathlas hits a coverage floor — TheoremSearch withheld 85% of their private 9.2M corpus, so 95 target papers are unreachable for any open system. The AI then runs the loop: for each missing theorem it web-finds the real statement, embeds it with the same Qwen3-Embedding-8B, and add_finding(dense_vec=…) fuses it through the dense channel at runtime (re-measured 2026-06-10 on the served 3.68M index — the after-loop headline reproduced exactly; the corpus-only baseline dipped 13.6% → 11.8% paper-level from the added Dolma distractors, reported as is):
| Method | theorem Hit@20 | paper Hit@20 |
|---|---|---|
Google (site:arxiv.org) | — | 37.8% |
| ChatGPT 5.2 w/ Search | 19.8% | — |
| Gemini 3 Pro | 27.0% | — |
| TheoremSearch (Qwen3-8B, full private 9.2M) | 45.0% | 56.8% |
| mathlas — baseline (corpus-only) | 10.0% | 11.8% |
| mathlas — after self-augmenting web loop | 59.1% (65/110) | 70.0% (77/110) |
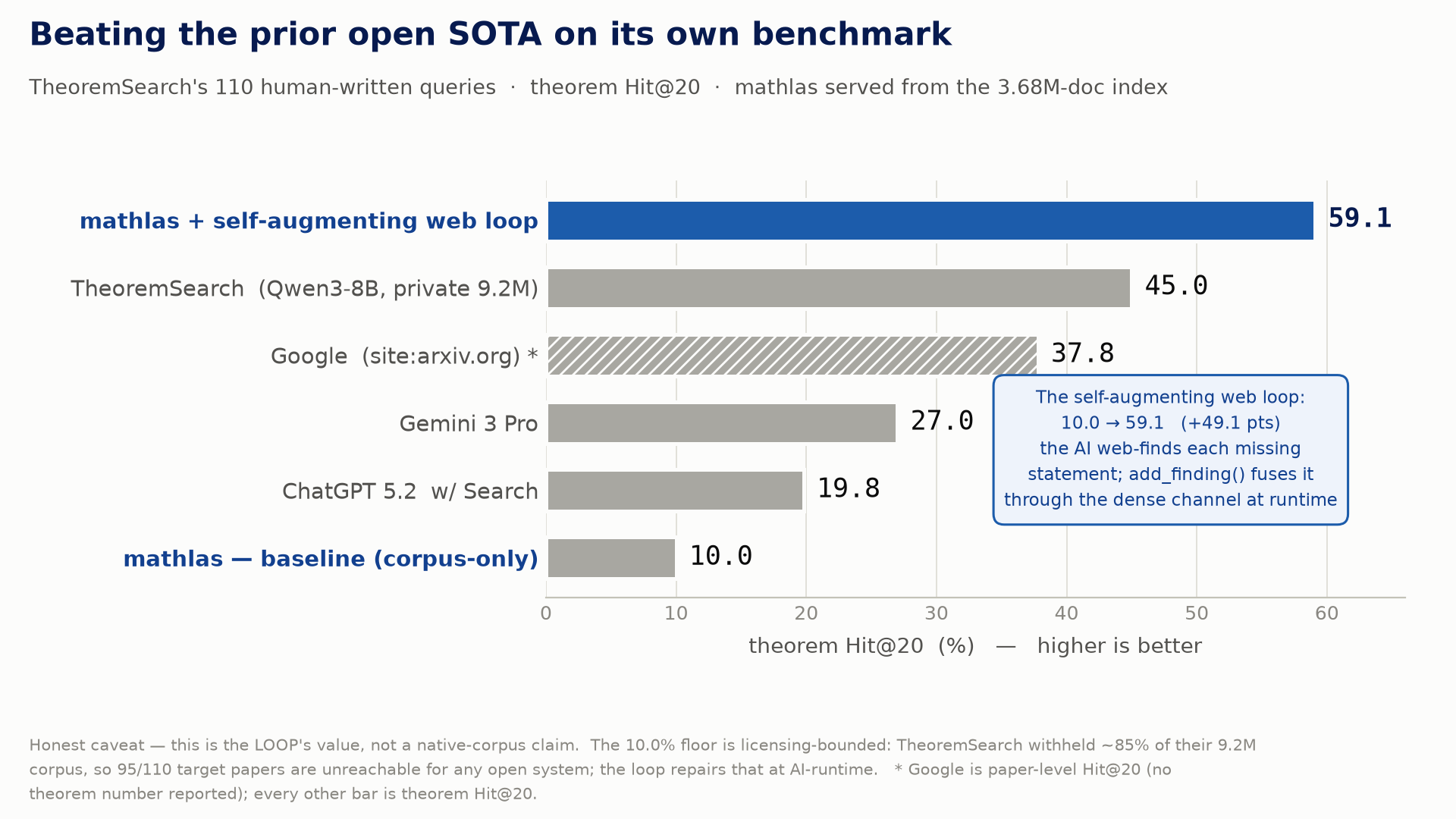
This is the loop's value, not a native-corpus claim. The 10.0% baseline is licensing-bounded — TheoremSearch withheld ~85% of their 9.2M corpus, so 95/110 target papers are unreachable for any open system; the self-augmenting web loop repairs that coverage gap at AI-runtime. Google's bar is paper-level Hit@20 (no theorem number reported); every other bar is theorem Hit@20.
Reproduce with benchmarks/webaug_110_bench.py (use the full 82-finding worklist _findings_worklist_full.json).
Source-aware retrieval (opt-in). Growing the index 1.34M → 3.68M had a measured cost: the 2.34M web-mined Dolma docs crowd canonical papers out of the top-20 (corpus-only paper-level 13.6% → 11.8% on these same 110 queries). search_existing_math now takes optional source_filter / source_weights — e.g. source_filter={"exclude": ["dolma"]} when you want canonical theorem statements only — and excluding dolma fully recovers the pre-growth 13.6% paper-level (15/110; reachable-15 paper 15/15 = 100%) with theorem-level above the old index (11.8% vs 10.9%). The default ranking stays byte-identical (test-pinned). It is a per-query-intent knob, not a free win: on the n=3000 self-recall, 65% of whose targets ARE Dolma docs, down-weighting dolma is catastrophic for those queries (dolma-target R@10 0.999 → 0.884 at weight 0.5, → 0 when excluded) — exactly why it ships opt-in, default off. We also tested whether the dual channel fixes this regression structurally, without the knob: it recovers part of it (paper 11.8% to 12.7%, theorem 10.0% to 10.9% at default settings) but not the full 13.6%, so the knob remains the documented mitigation on this benchmark. Full matrix: docs/02_eval_vs_theoremsearch.md.
The 12 tools

search_existing_math ─▶ mapping_scaffold + applicability_checklist ─▶ (AI judges) ─▶ verify_numeric / verify_formal
(own index) (needs↔guarantees, no LLM) (airtight)
Core four — what most agents use:
| Tool | What it does |
|---|---|
search_existing_math(query, k) | query → ranked results from the 3.68M-doc dense + BM25 + RRF index |
identify_constant(value) | a real value → known closed form + provenance (50-digit re-eval) |
verify_numeric(value, closed_form) | digit-agreement verdict — different engine, higher precision |
verify_formal(statement, lean?, proof?) | runs the real Lean kernel — typecheck a snippet, or pass proof to kernel-check a full Lean 4 proof: VERIFIED_PROOF / REFUTED (the kernel's exact error, for the repair loop) / honest UNDETERMINED |
Full toolkit:
| Tool | What it does |
|---|---|
search_formal_math(query, backend) | mathlib declaration names + types via the public Loogle (pattern/type) + LeanSearch (natural language) services, provenance-labeled; honest "service unavailable" — with a 7-day on-disk cache that serves the last good response when a service is down, clearly labeled (cached, <age> old) |
identify_sequence(terms) | integer sequence → matching OEIS entries (exact term-match) |
applicability_checklist(statement) | result's hypotheses as an atomic checklist for the AI to mark |
mapping_scaffold(problem, statement) | needs↔guarantees questions + fill-in template |
conjecture_relation(value) | Ramanujan Machine: PSLQ over rich basis + CF/recurrence conjectures |
funsearch(action, problem_id, …) | FunSearch harness in one tool — action=evaluate (sandbox-score an AI-written program), register (MAP-Elites DB), status (best + few-shot) |
search_directive(problem) | web-search plan: arXiv queries + sub-fields + which tools to run |
add_finding(statement, slogan, source) | ingest a web-found result into the live corpus |
All tools return data. No tool calls an LLM. search_formal_math is the one tool that itself makes a web call (to the public Loogle/LeanSearch services); everything else is fully local.
Proof checking — the repair loop
verify_formal doesn't just typecheck statements: give it a proposition and your Lean 4 proof, and the real kernel checks the full declaration. mathlas never writes a proof (the generator/verifier split is absolute) — but when your proof is wrong, the kernel tells you exactly why, verbatim, in kernel_error. That turns proof writing into a tight loop: the agent writes a proof → mathlas's kernel says exactly what's wrong → the agent repairs and re-calls.
verify_formal(statement="∀ n : Nat, n + 0 = n", proof="by\n intro n\n rfl")
// → {"proof_status": "VERIFIED_PROOF", "checked": true, ...}
verify_formal(statement="2 + 2 = 5", proof="rfl")
// → {"proof_status": "REFUTED", "kernel_error": "error: Not a definitional equality:
// the left-hand side 2 + 2 is not definitionally equal to the right-hand side 5 ...", ...}
No fake passes, by construction: sorry/admit holes are REJECTED (Lean itself exits 0 on a sorried proof — mathlas scans the source and the kernel's sorryAx diagnostics); a missing toolchain, a timeout (60 s cap), or an import this bare toolchain can't resolve all return an honest UNDETERMINED, never a verdict. The whole contract is pinned by tests/test_proof_check.py (20 tests against the real Lean 4.31.0 kernel: correct term and tactic-block proofs verified, wrong proofs refuted with the kernel's message, sorried proofs rejected, toolchain-absent honest).
CLI / Python
mathlas 1.6449340668482264364724151666460251892 # -> pi**2/6 [verified 51 digits]
mathlas 1,1,2,3,5,8,13,21 # -> A000045 Fibonacci https://oeis.org/A000045
mathlas "a bounded sequence has a convergent subsequence" --k 5 # search + scaffold
mathlas mcp # run the MCP server
import mpmath
from mathlas import identify, identify_sequence, mapping_scaffold, applicability_checklist
print(identify(mpmath.zeta(2))) # -> pi**2/6 [verified 51 digits]
print(identify_sequence([1,1,2,3,5,8,13,21]).matches[1].a_number) # -> 'A000045'
Docs
RESULTS.md— every tool's validation, reproduced, with commands.docs/methods.md— architecture, design decisions, citations.docs/05_open_dataset.md— the open dataset & the index.docs/QUANTIZED_TIER.md— the quantized laptop tier: measured recall/footprint/latency.docs/02_eval_vs_theoremsearch.md— the retrieval head-to-head.docs/REGISTRY_PUBLISH.md— publishing to the official MCP registry.
Positioning — retrieval is table stakes; verification is the moat
Credit where due: the closest system, TheoremSearch (UW Math AI Lab), now ships a production REST API and its own MCP endpoint (api.theoremsearch.com/mcp) over a 9.2M-document corpus — on raw recall over math literature it is the system to beat, and "we're MCP-native, they're a lab tool" is no longer a differentiator. We reuse only their openly-licensed (CC-BY/CC0) dataset subset as raw data for our own index — not their API, MCP, index, or code.
The DeepMind signal, and why an open verifier still matters. DeepMind's AlphaProof Nexus (arXiv:2605.22763) validates precisely mathlas's architecture — an LLM agent orchestrating a Lean kernel and structured math resources like OEIS as the ground-truth oracle — but it is internal-only: the public artifact is a results dump (google-deepmind/alphaproof-nexus-results), not a runnable system, with no API and no MCP surface. Gemini Deep Think and its peers only sharpen the need: as agents reason harder, an agent-side local, deterministic verifier it can call cheaply and offline becomes the bottleneck, not the model. mathlas remains the only open, no-API-key, MCP-composable verification layer any agent can drop in today — and it now also ingests DeepMind's own openly-licensed formal-conjectures Lean corpus (arXiv:2605.13171) as an index source (scripts/fetch_formal_conjectures.py, 3,941 Lean conjecture statements, source tag formal_conjectures, including the frozen FC100SolvedSet1/FC100OpenSet1 eval subsets).
Naming note: mathlas is unrelated to Matlas (matlas.ai, Peking University theorem search, arXiv:2604.17484) — different project, different authors; the near-homophone is coincidental.
What no competitor has is everything that happens after retrieval:
- Verification tiers —
verify_numeric(independent 50-digit re-evaluation) andverify_formal(a real Lean kernel typecheck — including full proof checking with the kernel's error returned verbatim for agent repair loops — or an honest UNDETERMINED). Retrieval hands you a candidate; mathlas can also check the claim and check your proof of it. applicability_checklist— decomposes a candidate theorem into atomic preconditions the AI verifies one by one, catching misapplications (open vs closed interval, infinite vs finite group). No competitor has one.- The self-augmenting
add_findingloop — the AI web-finds a missing statement, embeds it, and fuses it into the live index at runtime: 59.1% vs TheoremSearch's 45.0% theorem Hit@20 on their own 110-query benchmark (see above). This is, to our knowledge, the first math-domain instantiation of a validated-writeback RAG loop — the family of bidirectional retrieval systems that write verified inference back into the retrievable store (Bidirectional RAG, arXiv:2512.22199), rather than treating retrieval as read-only (Self-RAG, arXiv:2310.11511; CRAG, arXiv:2401.15884). What makes the math domain the right place for it: the write-back candidate can be deterministically checked (verify_numeric/verify_formal) before it is trusted, so the loop grows the corpus without the hallucination-amplification risk a generic writeback loop carries. - Zero-false-positive discipline — every tier returns an independently-checkable fact or an honest "nothing"; measured false-positive rate is 0 across all tiers (
RESULTS.md). - Free, no API key, provenance-labeled — every result carries where it came from (
known_constant,conjectured_relation,web_added,external:loogle, …), and the index is built 100% from openly-licensed data.
| mathlas | TheoremSearch | LeanSearch / Loogle | Wolfram MCP | sympy-mcp | |
|---|---|---|---|---|---|
| Informal math retrieval | ✅ 3.68M docs, open | ✅ 9.2M docs (~85% private) | ❌ (mathlib decls only) | ❌ | ❌ |
| Formal (mathlib) search | ✅ proxies both → one MCP tool | ❌ | ✅ (is exactly this) | ❌ | ❌ |
| Numeric verification | ✅ airtight 50-digit re-eval | ❌ | ❌ | ⚠️ CAS eval | ⚠️ CAS (no claim-check framing) |
| Formal verification | ✅ real Lean kernel (statements and full proofs, repair-loop errors) | ❌ | ❌ (search, not check) | ❌ | ❌ |
| Applicability checklist | ✅ unique | ❌ | ❌ | ❌ | ❌ |
| Self-augmenting corpus | ✅ add_finding (59.1 vs 45.0 Hit@20) | ❌ | ❌ | ❌ | ❌ |
| Constant/sequence ID | ✅ PSLQ + OEIS + Ramanujan-Machine | ❌ | ❌ | ⚠️ some | ❌ |
| Provenance labels | ✅ every result | ❌ | n/a | ❌ | n/a |
| Cost / key | free, no key | free endpoint | free | paid Wolfram API key | free |
| MCP | ✅ stdio, uvx one-liner | ✅ remote endpoint | ❌ (mathlas proxies them) | ✅ | ✅ |
(sympy-mcp is a fine CAS-manipulation server — its scope barely overlaps: it rewrites expressions you give it; mathlas finds, scopes, and verifies existing math.)
Official MCP registry
mathlas is published as io.github.Archerkattri/mathlas (see docs/REGISTRY_PUBLISH.md and server.json).
mcp-name: io.github.Archerkattri/mathlas
Featured
Integrate web data into your AI product. One API to scrape website & brand data.
Get API Key Now →belt cli automatically finds the best tools and skills for your agent. image, video, music, tts...
one prompt install →Give your AI agent a complete email layer—sending, inbound inboxes, and sandbox testing.
Get 4K emails/month free →Agent, run crypto. Access onchain data & trade routes via 1inch.
Install now →Notes, actions and memory. Without a meeting bot. First month 100% off.
Download for free →Your agent targets a perfect 10 Code Health score. Deterministic. Every commit.
Try For Free →Configuration
MATHLAS_SEEDSet to 1 to force the lightweight built-in seed corpus and never load the multi-GB prebuilt index (fast cold start).
MATHLAS_INDEXPath to a prebuilt index .npz to serve for search_existing_math (optional; the seed corpus is used when absent).
Categories
Registryactive
Packagemathlas-mcp
TransportSTDIO
UpdatedJun 10, 2026