
Summary
Marm Systems provides an intelligent persistent memory system for AI agents that maintains long-term recall and session continuity through conversation history management, supporting both HTTP and STDIO transport protocols. The server offers tools for storing, retrieving, and managing conversation context so that language models can accurately reference previous interactions without losing track of important information. It solves the problem of AI agents losing context across sessions by providing reliable, controlled memory storage that prevents conversation drift and enables stateful, continuous interactions.
Agent, run crypto. Access onchain data & trade routes via 1inch.
Install now →On Capafy, your Skill runs online 24/7 as an agent product, and you get paid every time someone uses it.
Start earning →Connect Claude to +800M contacts, +150M companies. Find & Enrich leads in chat.
Try For Free →Integrate web data into your AI product. One API to scrape website & brand data.
Get API Key Now →MARM: Local-First Persistent Multi-Agent Memory Layer for MCP Clients v2.14.2


![]()
![]()

Contributions welcome! Browse open issues to contribute, or join the MARM Discord to share workflows, get setup help, and connect with other builders.
Table of Contents
- Why MARM MCP
- Quick Start
- Connect Your Client Fast
- Complete MCP Tool Suite
- MARM Dashboard
- Why MARM Holds Up
- Performance & Scaling Benchmarks
- Contributing
- Project Documentation
Why MARM MCP: The Problem & Solution
Your AI forgets everything. MARM MCP doesn't.
MARM MCP is a local memory infrastructure layer for AI agents. It gives Claude, Codex, Gemini, Qwen, IDE agents, and other MCP clients one persistent place to store decisions, retrieve context, reuse notebooks, and keep long-running work from drifting.
The point is not "more tools." MARM exposes 7 focused MCP tools and moves the heavy work behind the server: session routing, protocol delivery, hybrid recall, serialized writes, rate-limit presets, write-time consolidation, and agent-assisted compaction. Because the tool surface stays small, re-ranking filters results before they reach the model, and consolidation catches duplicates at write time, token spend stays low and predictable as workloads grow.
How It Works
| Layer | What it does | Why it matters |
|---|---|---|
| Memory model | Sessions, structured logs, notebooks, summaries, and semantic memories | Keeps project history searchable instead of trapped in one chat |
| Scale layer | SQLite WAL mode, connection pooling, serialized write queue, and HTTP rate-limit presets | Lets one server support solo use, multi-agent work, and swarm-style bursts |
| Intelligence layer | FTS filter, semantic re-rank, bounded semantic fallback, auto-classification, write-time consolidation, and compaction candidates | Keeps recall useful as memory grows instead of letting duplicates pile up |
| Token layer | Lightweight 7-tool surface, semantic re-rank before retrieval, and write-time deduplication | Reduces tokens sent to the model on every recall and cost stays predictable as memory scales |
| Deployment layer | Pip, Docker, STDIO, HTTP, --swarm, --swarm-max, and --trusted | Lets you run private local memory or shared multi-agent memory with the same MCP surface |
See Performance & Scaling Benchmarks for retrieval latency, concurrency, and write-cost numbers.
MARM Demo
https://github.com/user-attachments/assets/dabfe44f-689d-404f-a2c7-dcf8fa4ef0c1
MARM gives AI agents persistent local memory, shared context, write-queue safety, swarm presets, and hybrid recall so commands, config keys, and project meaning all stay reachable.
Start Now (pip)
Install once:
pip install marm-mcp-server
| If you are... | Start the server | Connect your MCP client |
|---|---|---|
| Solo developer / researcher | python -m marm_mcp_server | "agent" mcp add --transport http marm-memory http://localhost:8001/mcp |
| Private local STDIO user | marm-mcp-stdio | "agent" mcp add --transport stdio marm-memory-stdio marm-mcp-stdio |
| Multiple agents sharing memory | python -m marm_mcp_server --swarm | "agent" mcp add --transport http marm-memory http://localhost:8001/mcp |
| Private high-throughput swarm | python -m marm_mcp_server --swarm-max | "agent" mcp add --transport http marm-memory http://localhost:8001/mcp |
| Trusted private lab/server | python -m marm_mcp_server --trusted | "agent" mcp add --transport http marm-memory http://localhost:8001/mcp |
What Users Are Saying
“MARM successfully handles our industrial automation workflows in production. We've validated session management, persistent logging, and smart recall across container restarts in our Windows 11 + Docker environment. The system reliably tracks complex technical decisions and maintains data integrity through deployment cycles.”
@Ophy21, GitHub user (Industrial Automation Engineer)
“MARM proved exceptionally valuable for DevOps and complex Docker projects. It maintained 100% memory accuracy, preserved context on 46 services and network configurations, and enabled standards-compliant Python/Terraform work. Semantic search and automated session logs made solving async and infrastructure issues far easier. Value Rating: 9.5/10 - indispensable for enterprise-grade memory, technical standards, and long-session code management.” @joe_nyc, Discord user (DevOps/Infrastructure Engineer)
🚀 Quick Start for MCP (HTTP & STDIO)
Use this quick rule of thumb to choose your setup
- Local HTTP/STDIO = fastest single-machine setup.
- Docker HTTP = shared/always-on server (key required).
- Docker STDIO = private containerized local use (no HTTP key).
Swarm / multi-agent note: The write queue is enabled by default to serialize memory writes through one worker. For shared HTTP deployments, use --swarm (200 RPM) or --swarm-max (600 RPM) when starting the server. --trusted disables rate limiting entirely for private deployments. STDIO is still best for private single-agent/local use. Run one MARM HTTP process per SQLite database; uvicorn --workers N / multi-process workers are not supported yet because queue, scheduler, and protocol coordination are process-local.
Local pip HTTP (zero config)
"agent" refers to claude, gemini, grok, qwen, or any MCP client. Codex uses --url instead of --transport to add MCP tools.
pip install marm-mcp-server
# Stuck on client setup? Open a Q&A thread: https://github.com/Lyellr88/MARM-Systems/discussions
# most agents use this --transport command
"agent" mcp add --transport http marm-memory http://localhost:8001/mcp
codex mcp add marm-memory --url http://localhost:8001/mcp
# xAI / Grok Remote MCP. Use a hosted HTTPS MARM endpoint, not localhost.
python -m marm_mcp_server
Local pip STDIO
pip install marm-mcp-server
# most agents use this --transport command
"agent" mcp add --transport stdio marm-memory-stdio marm-mcp-stdio
codex mcp add marm-memory-stdio -- marm-mcp-stdio
# xAI / Grok Remote MCP. Use a hosted HTTPS MARM endpoint, not localhost.
python -m marm_mcp_server.server_stdio
Docker HTTP (key required)
Docker HTTP requires an API key because it exposes MARM as a network server; STDIO stays local to the client process and does not need one.
# Step 1: generate key (do not add < > around the key)
docker run --rm lyellr88/marm-mcp-server:latest --generate-key
# Step 2: run server
docker pull lyellr88/marm-mcp-server:latest
docker run -d --name marm-mcp-server \
-p 127.0.0.1:8001:8001 \
-e SERVER_HOST=0.0.0.0 \
-e MARM_API_KEY=your-generated-key \
-v ~/.marm:/home/marm/.marm \
lyellr88/marm-mcp-server:latest
# Step 3: connect client
"agent" mcp add --transport http marm-memory http://localhost:8001/mcp --header "Authorization: Bearer your-generated-key"
codex mcp add marm-memory --url http://localhost:8001/mcp --bearer-token-env-var MARM_API_KEY
Docker HTTP swarm mode
# --swarm: write queue on, 200 RPM - recommended for multi-agent shared servers
docker run -d --name marm-mcp-server \
-p 127.0.0.1:8001:8001 \
-e SERVER_HOST=0.0.0.0 \
-e MARM_API_KEY=your-generated-key \
-v ~/.marm:/home/marm/.marm \
lyellr88/marm-mcp-server:latest --swarm
Docker STDIO (no HTTP key)
docker run --rm -i \
-v ~/.marm:/home/marm/.marm \
--entrypoint python \
lyellr88/marm-mcp-server:latest \
-m marm_mcp_server.server_stdio
Most useful support info:
- Docker HTTP requires a key; Docker STDIO does not.
- If you get
401, verify key match and client restart after env var changes. - For full key setup, rotation, and troubleshooting: INSTALL-DOCKER.md
Connect Your Client Fast
Claude Code remains the recommended first setup path, but MARM also works with other MCP clients and IDE agents.
CLI clients - Claude Code · Codex · Gemini CLI · Qwen CLI · Linux variants · Docker/key
IDE agents - VS Code / Copilot Agent · Cursor · Docker/key IDE setup
Remote/API platforms - xAI / Grok Remote MCP · Platform integration
Using a client that isn't listed? Open an issue and let us know; client adapters are a first-class feature request.
MARM Dashboard
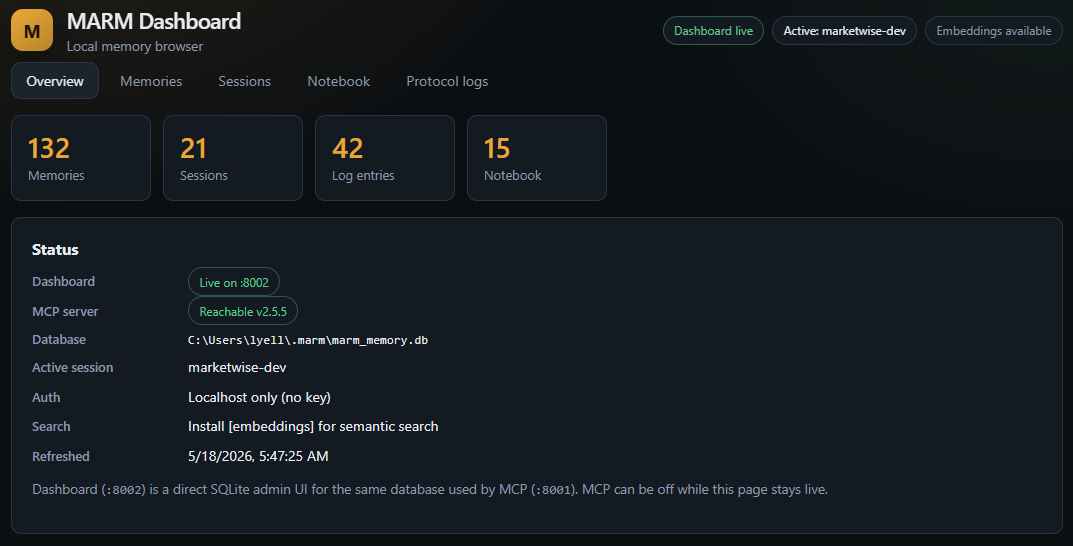
A local web UI for browsing and managing your MARM memory; separate from the MCP server, reads and writes the same ~/.marm/marm_memory.db.
| What it gives you | How it works |
|---|---|
| Browse/search/edit all memories | Direct SQLite - no MCP required |
| Manage sessions and protocol logs | Runs on port :8002 alongside MCP on :8001 |
| Notebook CRUD with inline editor | Same auth model (MARM_API_KEY) as the MCP server |
| Delete-all with count confirmation | Docker image included; WAL mode handles concurrent access |
# Quick start (pip)
cd marm-dashboard
pip install -e .
python -m marm_dashboard --open
# Docker (same key and volume as MCP)
docker build -t marm-dashboard:local ./marm-dashboard
docker run --rm -p 127.0.0.1:8002:8002 \
-e MARM_API_KEY=your-key \
-v ~/.marm:/home/marm/.marm \
marm-dashboard:local
See marm-dashboard/README.md for the full guide.
Complete MCP Tool Suite (7 Tools)

💡 Pro Tip: You don't need to manually call these tools! Just tell your AI agent what you want in natural language:
- "Claude, log this session as 'Project Alpha' and add this conversation as 'database design discussion'"
- "Remember this code snippet in your notebook for later"
- "Search for what we discussed about authentication yesterday"
The AI agent will automatically use the appropriate tools. Manual tool access is available for power users who want direct control.
Architecture note: MARM groups related operations behind a single dispatching tooling to keep MCP discovery lean without hiding behavior. Domain-specific tools such as marm_notebook(action=...), marm_delete(type=...), and marm_compaction(action=...) group closely related operations behind explicit parameters, while recall, logging, and summaries stay separate so agents still choose the right capability clearly. This design keeps the MCP schema compact while preserving full functionality.
Project/platform attribution: new memories, logs, and notebook entries are tagged with nullable project and platform metadata when MARM can detect them. MARM_PROJECT can override the detected working-directory project, and MARM_PLATFORM can override the detected client/platform. marm_smart_recall accepts optional project and platform filters, including when include_logs=True, so agents can ask for context from a specific project or client without losing normal cross-project search.
| Category | Tool | Description |
|---|---|---|
| Memory Intelligence | marm_smart_recall | AI-powered recall across all memories. Uses FTS5 BM25 to filter exact-term candidates first, semantically re-ranks that bounded set by embedding similarity, falls back to bounded semantic scanning when FTS coverage is weak, and scores long memories through chunked embeddings while still returning one parent memory result. Supports global search with search_all=True, attribution filters with project/platform, and summary/context/full memory depth with detail=1/2/3 |
| Logging System | marm_log_entry | Add structured session log entries. Session/topic routing, summary-cache invalidation, and context summary preparation are handled by the server |
marm_log_show | Display all entries and sessions (filterable) | |
marm_delete | Delete a log session, log entry, or notebook entry (type="log"|"notebook") | |
| Reasoning & Workflow | marm_summary | Generate cached session summaries with intelligent truncation for LLM conversations |
| Notebook Management | marm_notebook | Unified notebook tool: add, use, show, status, or clear entries with action="add"|"use"|"show"|"status"|"clear" |
| Memory Maintenance | marm_compaction | Unified compaction workflow with action="status"|"candidates"|"review"|"stage"|"apply"|"discard" for agent-assisted memory cleanup |
Internal automation: lifecycle initialization, protocol delivery with periodic protocol-lite refresh, documentation refresh, current date context, summary-cache maintenance, serialized write queue handling, and system checks are handled by the server instead of exposed as AI-facing tools. Optional compaction can detect duplicate memory clusters and nudge the connected agent to summarize them through marm_compaction. For server status, use the dashboard health panel or curl http://localhost:8001/health.
Why MARM Holds Up
MARM keeps the AI-facing surface small while the server handles the infrastructure work:
- Write stability: SQLite WAL mode, connection pooling, and a serialized write queue are enabled for normal use.
- Swarm control: HTTP presets tune shared access: default
80 RPM,--swarm200 RPM,--swarm-max600 RPM, and--trusteddisables rate limiting for private deployments. - Cleaner recall: FTS filter→semantic re-rank, bounded semantic fallback, chunked long-memory embeddings, conservative temporal weighting, write-time consolidation, and optional compaction reduce duplicate/noisy memories over time.
- Lower token burn:
marm_smart_recallcan return summary, context, or full-memory depth so agents do not pull full bodies unless they need them. - Long-memory coverage: memories that exceed the base embedding window are chunked internally and scored by best-matching chunk, so late-body details stay recallable without flooding results with duplicate chunk hits.
- Safe defaults: local pip binds to
127.0.0.1; Docker HTTP requiresMARM_API_KEY; STDIO stays private and keyless.
For deeper architecture, configuration, and workflow guidance, use MCP-HANDBOOK.md and FAQ.md.
Performance & Scaling Benchmarks
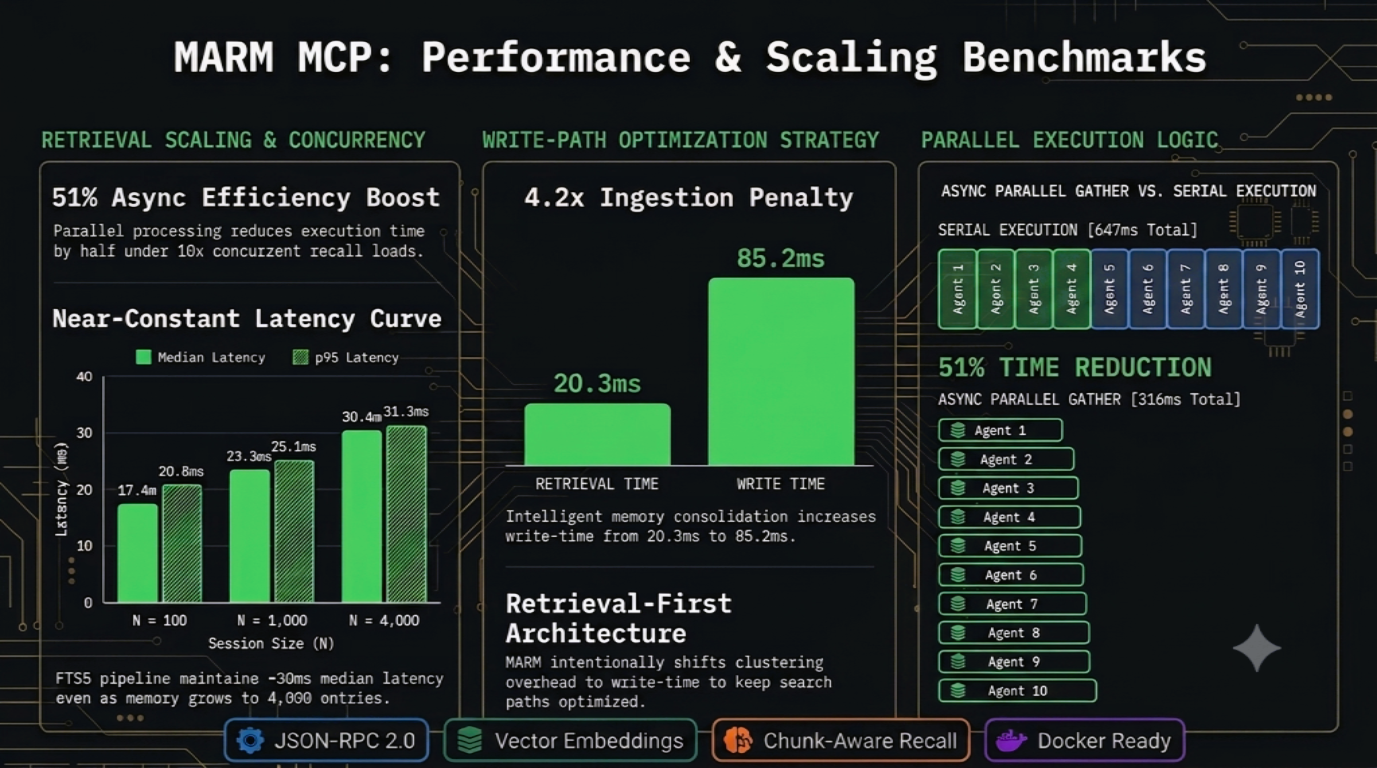
MARM is optimized for low-latency retrieval and multi-agent concurrency. The following benchmarks were executed locally to test database scaling, event-loop blocking, and write-time compaction penalties.
1. Retrieval Latency Scaling
Measured across varying session history sizes ($N = \text{number of stored memories}$).
| Session Size ($N$) | Min Latency | Median Latency | p95 Latency |
|---|---|---|---|
| N = 100 | 12.0 ms | 17.4 ms | 20.8 ms |
| N = 500 | 12.4 ms | 20.5 ms | 22.6 ms |
| N = 1,000 | 15.9 ms | 23.3 ms | 25.1 ms |
| N = 4,000 | 23.1 ms | 30.4 ms | 31.3 ms |
Takeaway: The FTS5 filter $\rightarrow$ semantic re-rank pipeline delivers near-constant retrieval time regardless of memory store size, 17ms at N=100, 30ms at N=4,000.
2. Multi-Agent Concurrency (10x Concurrent Recalls)
Evaluates event-loop blocking when 10 independent agent requests hit the server simultaneously ($N=1000$).
- Serial Execution (Sequential): 647.0 ms
- Async Gather (Concurrent): 316.3 ms
- Efficiency Ratio:
0.49($51%$ execution time reduction under parallel load)
3. Write-Time Ingestion Cost
Evaluates the performance impact of turning on intelligent memory consolidation during store_memory operations ($N=800$).
- Consolidation OFF: 20.3 ms (Median)
- Consolidation ON: 85.2 ms (Median)
- Architectural Trade-off:
4.2xingestion penalty. MARM intentionally shifts clustering and deduplication overhead to write-time, ensuring retrieval paths stay aggressively optimized.
Benchmarks were run against a real SQLite database with the live all-MiniLM-L6-v2 encoder on local hardware. Reproduce them yourself: marm-mcp-server/scripts/bench_hotpath.py
⭐ Star the Project
If MARM helps with your AI memory needs, please star the repository to support development!
Contributing
MARM is open to useful contributions: bug reports, install feedback, documentation fixes, client connection notes, performance testing, and focused pull requests.
Good places to help:
- Test MARM with more MCP clients and IDE agents
- Improve install docs and platform-specific setup notes
- Report bugs with clear reproduction steps
- Suggest practical memory workflows and tool improvements
- Check out open issues
💡 Want to get your name on this list? Check out our CONTRIBUTING.md guide to get started!
Join the MARM Community
Help build the future of AI memory - no coding required!
Connect: MARM Discord | GitHub Discussions
Easy Ways to Get Involved
- Try the MCP server and share your experience
- Star the repo if MARM solves a problem for you
- Share on social - help others discover memory-enhanced AI
- Open issues with bugs, feature requests, or use cases
- Join discussions about AI reliability and memory
License & Usage Notice
This project is licensed under the Apache 2.0 License. Forks and derivative works are permitted. However, use of the MARM name and version numbering is reserved for releases from the official MARM repository. Derivatives should clearly indicate they are unofficial or experimental.
Project Documentation
Usage Guides
- MCP-HANDBOOK.md - Complete MCP server usage guide with commands, workflows, and examples
- PROTOCOL.md - MCP operating protocol
- FAQ.md - Answers to common questions about using MARM
MCP Server Installation
- INSTALL-DOCKER.md - Docker deployment (recommended)
- INSTALL-WINDOWS.md - Windows installation guide
- INSTALL-LINUX.md - Linux installation guide
- INSTALL-PLATFORMS.md - Platform installation guide
Project Information
- README.md - This file - ecosystem overview and MCP server guide
- CONTRIBUTING.md - How to contribute to MARM
- CHANGELOG.md - Version history and updates
- ACKNOWLEDGMENTS.md - Contributors and acknowledgments
- ROADMAP.md - Planned features and development roadmap
- LICENSE - Apache 2.0 license terms
Featured
Agent, run crypto. Access onchain data & trade routes via 1inch.
Install now →On Capafy, your Skill runs online 24/7 as an agent product, and you get paid every time someone uses it.
Start earning →Connect Claude to +800M contacts, +150M companies. Find & Enrich leads in chat.
Try For Free →Integrate web data into your AI product. One API to scrape website & brand data.
Get API Key Now →Categories
Registryactive
Packagemarm-mcp-server
TransportSTDIO
UpdatedJun 8, 2026